Overview
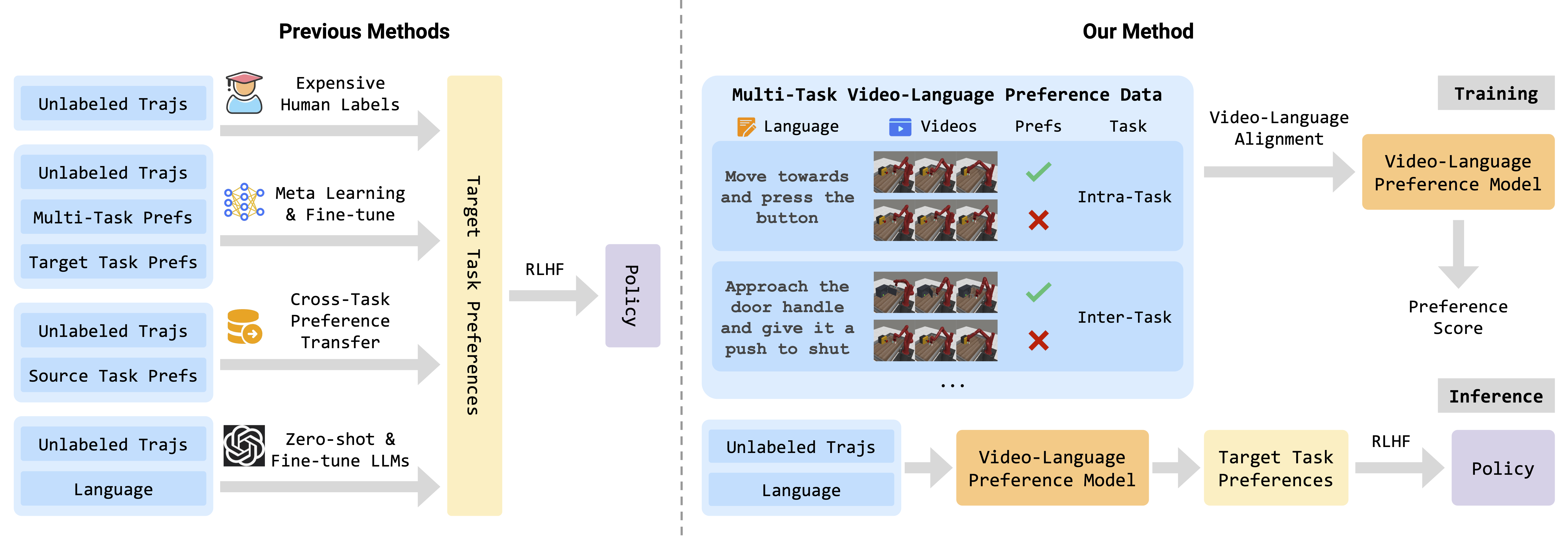
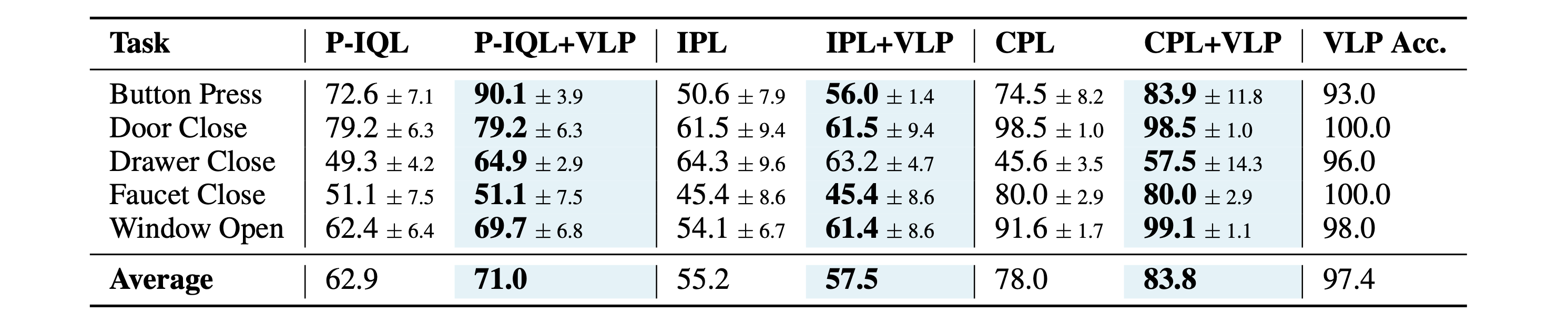
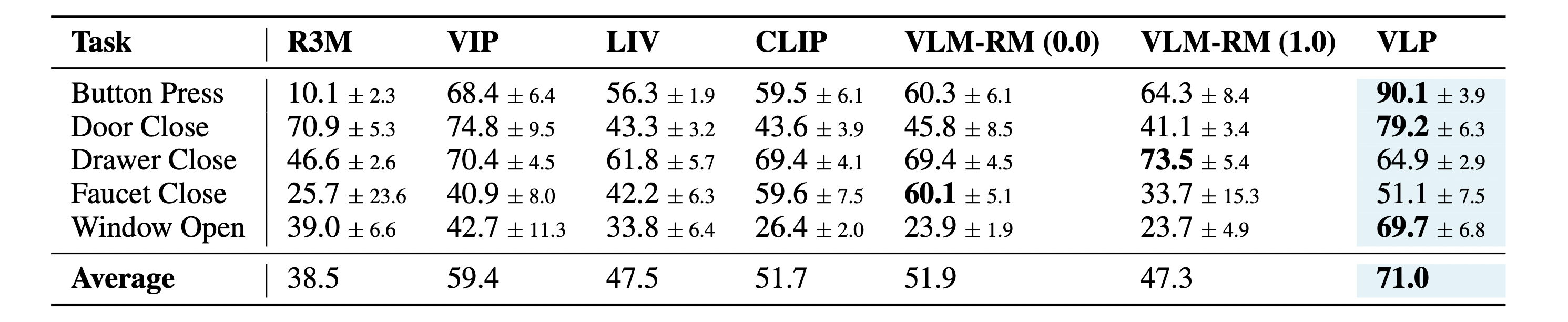
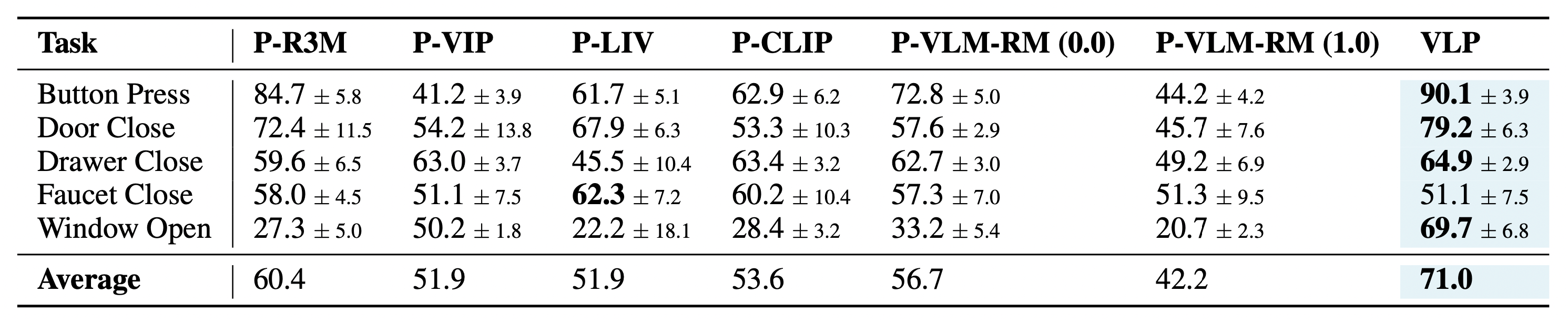
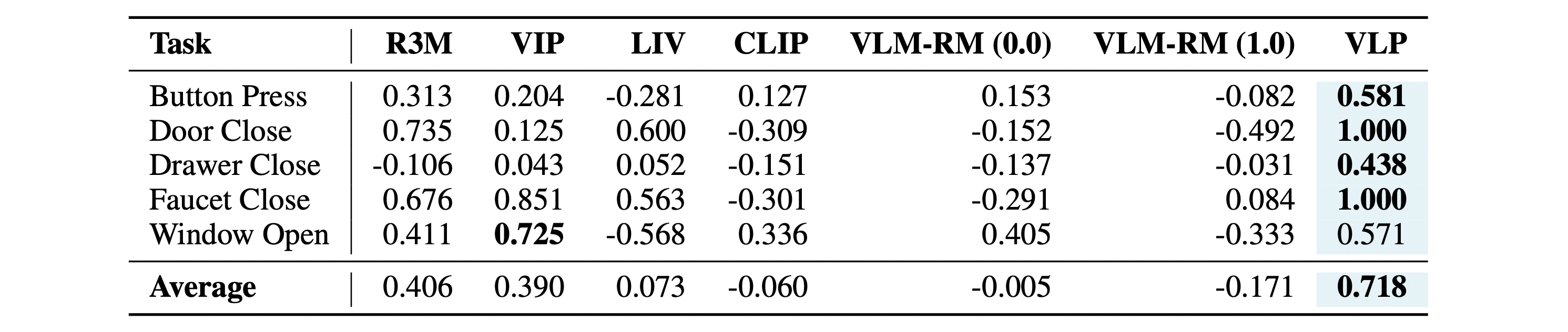
In this paper, we propose a novel Vision-Language Preference alignment framework, named VLP, to provide generalized preference feedback for video pairs given language instructions. Specifically, we collect a video dataset from various policies under augmented language instructions, which contains implicit preference relations based on the trajectory optimality and the vision-language correspondence. Then, we propose a novel vision-language alignment architecture to learn a trajectory-wise preference model for preference labeling, which consists of a vision encoder, a language encoder, and a cross-modal encoder to facilitate vision-language alignment. The preference model is optimized by intra-task and inter-task preferences that are implicitly contained in the dataset. In inference, VLP provides preference labels for target tasks and can even generalize to unseen tasks and unseen language. We provide an analysis to show the learned preference model resembles the negative regret of the segment under mild conditions. The preference labels given by VLP are employed for various downstream preference optimization algorithms to facilitate policy learning.